Recent Storage Performance Improvements at Neon
A look at what we’ve shipped in recent months, from smarter sharding to compressed WAL

Neon’s storage architecture is designed for scalability, but scalability alone doesn’t guarantee performance. Over the past several months, we’ve been focused on making the Neon storage system faster – cutting down ingest latency, reducing read amplification, making better use of disk and network bandwidth, and optimizing the path from write-ahead log to S3.
If you haven’t read our deep dive on Neon’s storage layer, it’s worth the background. In short – Neon splits storage across Safekeepers and Pageservers; Safekeepers receive WAL from Postgres; Pageservers turn that WAL into data, serve reads, and upload layers to S3. There are a lot of moving parts in our storage and plenty of opportunities to improve performance across them.
In this post, we recap the storage-side improvements we’ve shipped during the past months. We’re still not done, but these changes lay the groundwork for even more performance gains.
Sharded Pageserver Ingestion
TL;DR
How: WAL is now decoded once at the Safekeeper and routed only to the relevant shard instead of being broadcast to all.
Neon splits large tenants across multiple Pageservers to scale out storage and improve performance. This is what we call sharding. But until recently, every WAL record from Postgres was sent to all shards, even though each record typically only pertained to one. That meant every shard had to receive, decode, and discard irrelevant data, wasting both CPU and network bandwidth.
We’ve now changed that. WAL records are decoded once on the central Safekeepers and routed only to the appropriate Pageserver shard. The impact is significant: we reduce unnecessary work by a factor of (N−1)/N for N shards. With 8 shards, that’s an 87.5% reduction in WAL decoding work across the Pageservers.
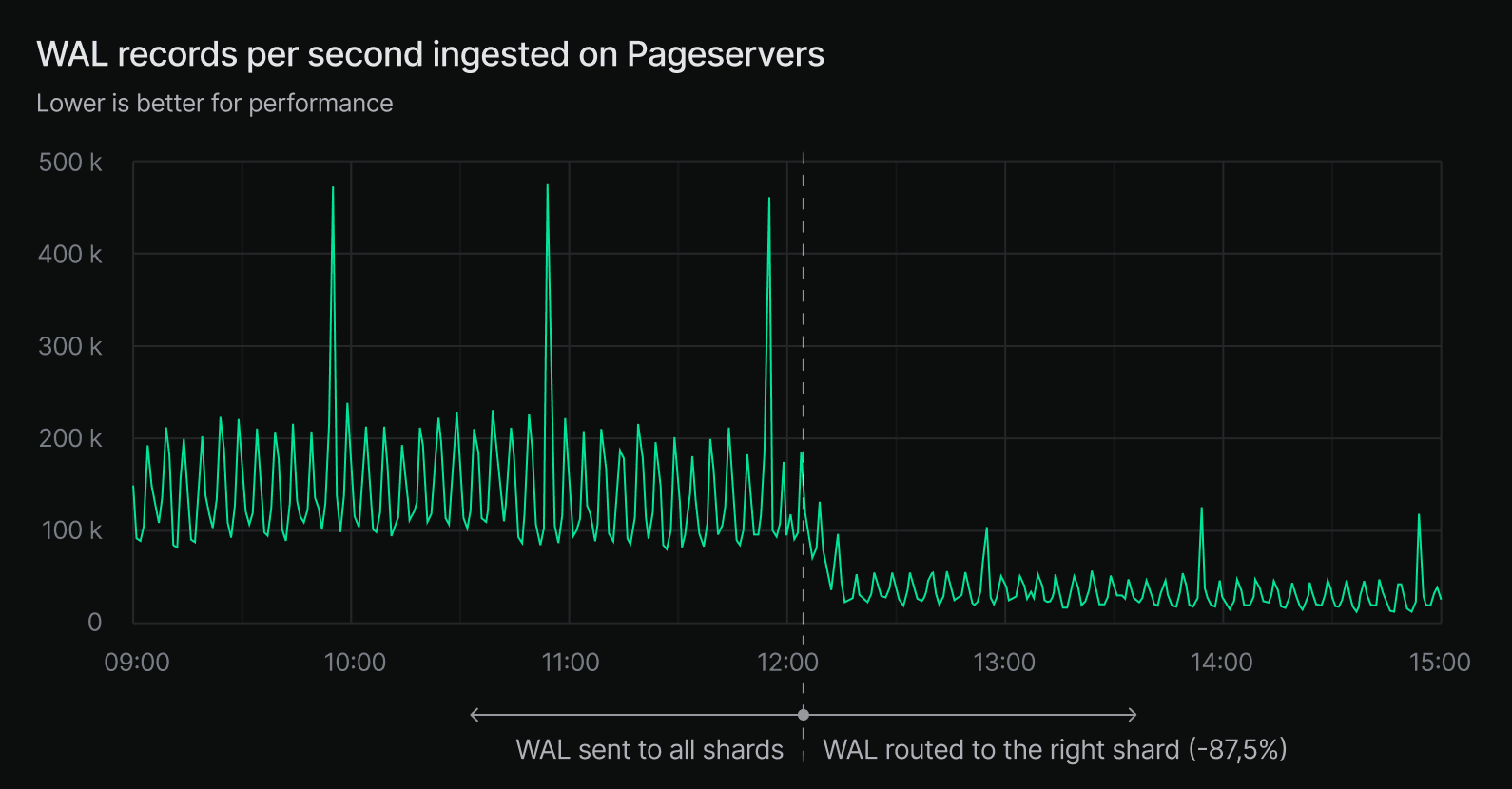
This doesn’t translate into an 8x speedup in ingestion (since the redundant work was done in parallel) but it does give shards more breathing room to keep up with compaction and other tasks. In practice, we’ve observed about a 2x improvement in ingest throughput for large tenants.
We also benchmarked a 200 GB COPY import workload. When sharded ingest was enabled in staging, cumulative import time dropped by ~50%. While that data is noisy and still being refined, it’s a clear signal that we’re headed in the right direction.
Compressed WAL Transmission
TL;DR
How: WAL records are now Protobuf-encoded and Zstd-compressed on Safekeepers before being sent to Pageservers
Previously, Neon’s Safekeepers sent WAL to Pageservers in an uncompressed format. The Pageservers would then decode, process, and store those records, a process that consumed significant network bandwidth.
We have a new path now, where safekeepers pre-process WAL into the Pageserver’s on-disk format, then Protobuf-encode and compress the data using Zstd before transmission. This offloads work from the Pageserver and drastically cuts down the amount of data transferred over the network.
In aggregate, this reduces WAL transmission bandwidth by around 70%. For example, during the rollout in eu-central-1 past January, we saw outbound Safekeeper traffic drop from ~250 MB/s to ~75 MB/s. That’s a clear and measurable bandwidth improvement.
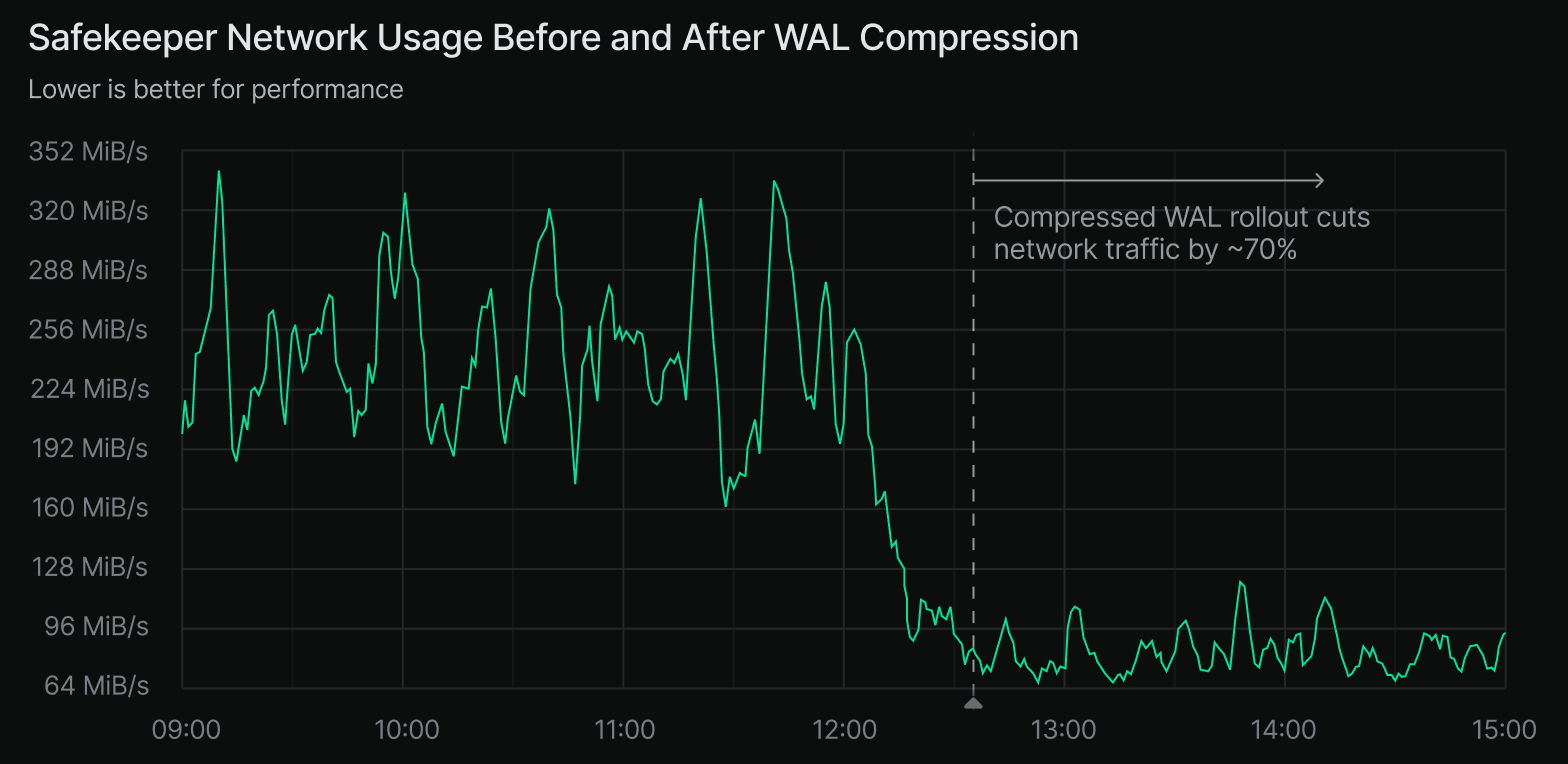
It’s worth noting that this change was deployed around the same time as sharded ingest, so the effects can be hard to separate at a macro level. But since most tenants are still unsharded, we can confidently attribute the majority of this bandwidth reduction to WAL compression.
Faster Safekeeper Disk Writes
TL;DR
How: WAL is now written to sparse files using ftruncate and avoids unnecessary fsync calls
Safekeepers are responsible for writing incoming WAL to disk. With our previous design, this involved allocating and flushing data in ways that weren’t optimal for performance especially under high ingest workloads. We introduced several changes to improve this:
- Sparse files via
ftruncate: Instead of writing full zeroed-out data segments, we allocate space more efficiently, allowing the file system to skip writing uninitialized data. - Avoiding disk flushes via
fsync: Where safe, we now delay or skip expensive flushes to disk, reducing I/O overhead.
Together, these changes yielded a 230% speedup in WAL write throughput in benchmarks. In one case using 128 KB WAL chunks, throughput increased from ~215 MiB/s to over 705 MiB/s:
wal_acceptor_throughput/fsync=true/commit=false/size=131072
time: [1.4305 s 1.4513 s 1.4727 s]
thrpt: [695.30 MiB/s 705.57 MiB/s 715.84 MiB/s]
change:
time: [-70.5% -70.1% -69.6%]
thrpt: [+229.0% +234.1% +239.0%]In terms of Safekeeper resource usage, we’ve seen an expected 50% reduction in disk bandwidth. Disk IOPS were also reduced, though we didn’t quantify that separately.
It’s important to note that Safekeepers typically aren’t the main bottleneck in Neon’s write path, but this change clears the way for more throughput and lower latency as other parts of the system improve.
Scan Prefetches
TL;DR
How: Pageserver now prefetches up to 100 sequential pages in scans to avoid one-at-a-time roundtrips.
When Postgres performs a sequential scan or an index scan, it often needs to read a large number of pages in order. If each page has to be fetched individually from the Pageserver over the network, this can become a major latency bottleneck.
To address this, we added support for page prefetching from Pageservers. When a compute begins a scan, it proactively fetches the next 100 pages (or fewer, depending on access patterns) from the Pageserver before they’re explicitly requested. This reduces the per-page roundtrip costs and speeds up the overall scan.
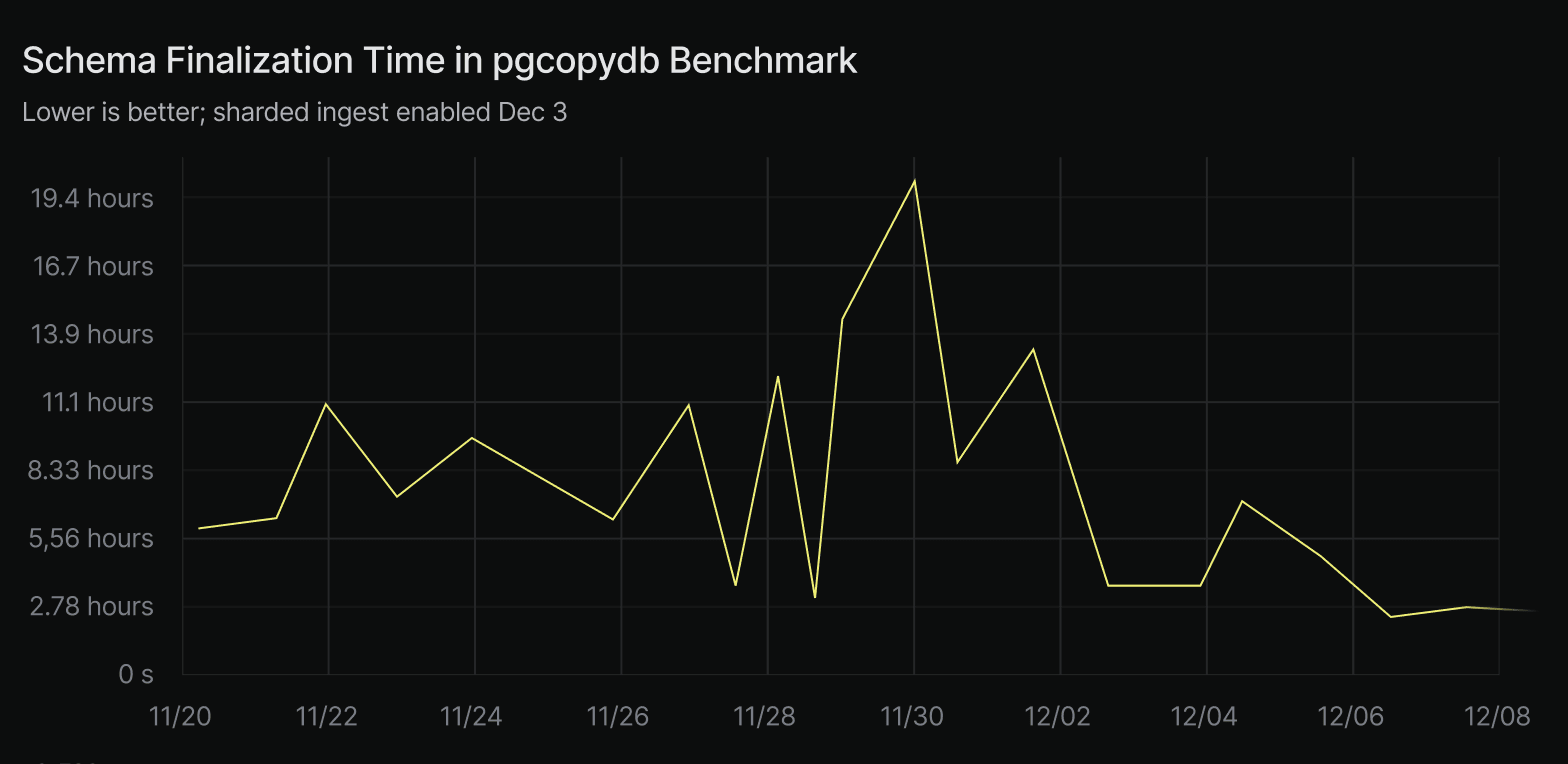
The performance gains are substantial. In a pgcopydb-based benchmark that imports data and builds constraints, enabling scan prefetches reduced schema finalization time (such as bulk foreign key creation) from 10 hours to 2.5 hours, a 300% speedup.
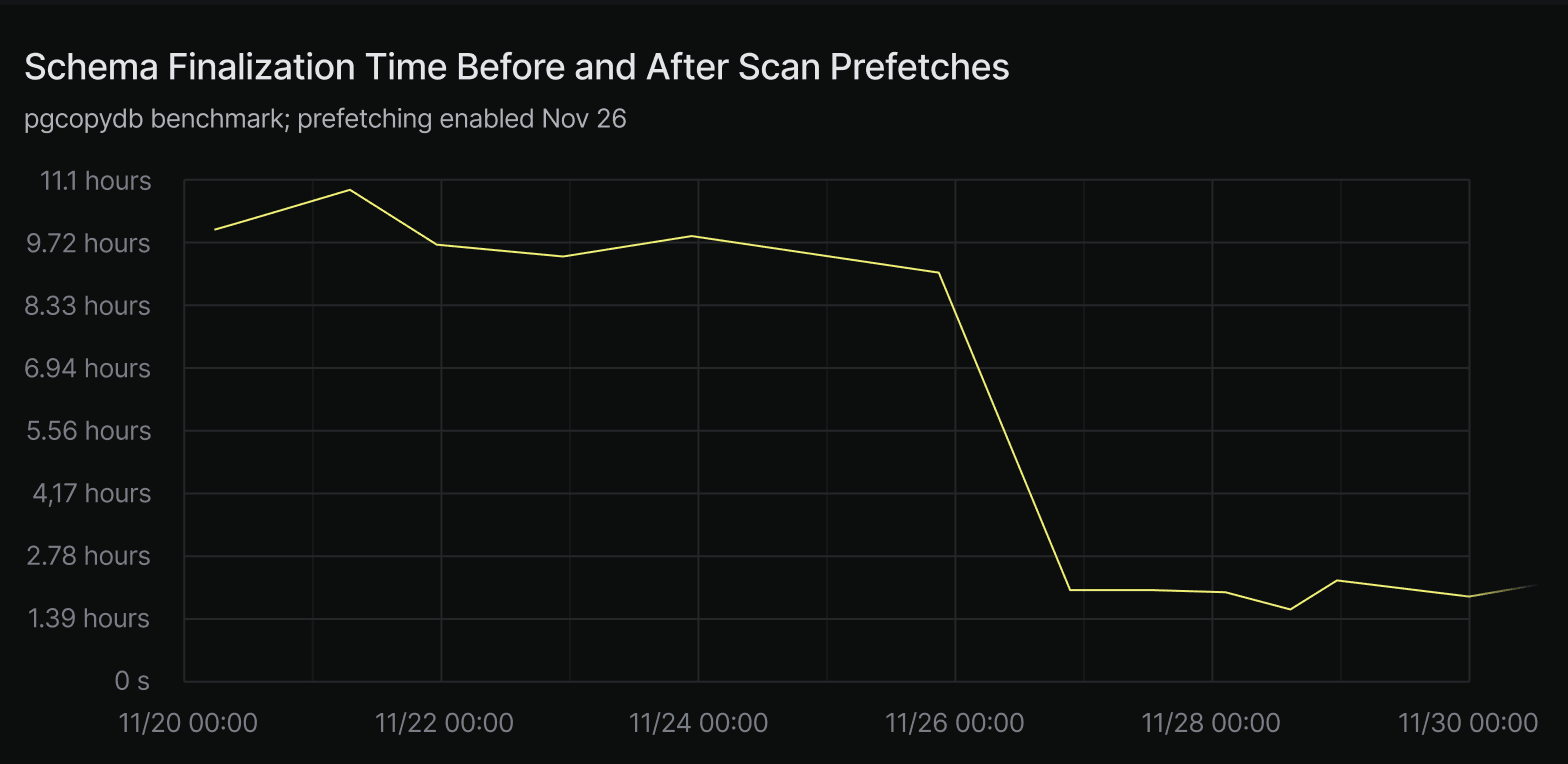
This change improves latency for large reads and helps bring Neon’s read performance closer to what users expect from a local Postgres setup, even when data is remote.
More Responsive L0 Compaction
TL;DR
How: L0 compaction is now prioritized over background tasks; ingestion is throttled when needed to let compaction catch up.
Neon’s storage engine uses a variant of an LSM tree. Incoming writes are first stored in L0 files, which are then compacted into more efficient L1 files. This process is essential: every read must search through all L0 files plus any relevant L1 files, and as the number of L0 files increases, so does read amplification.
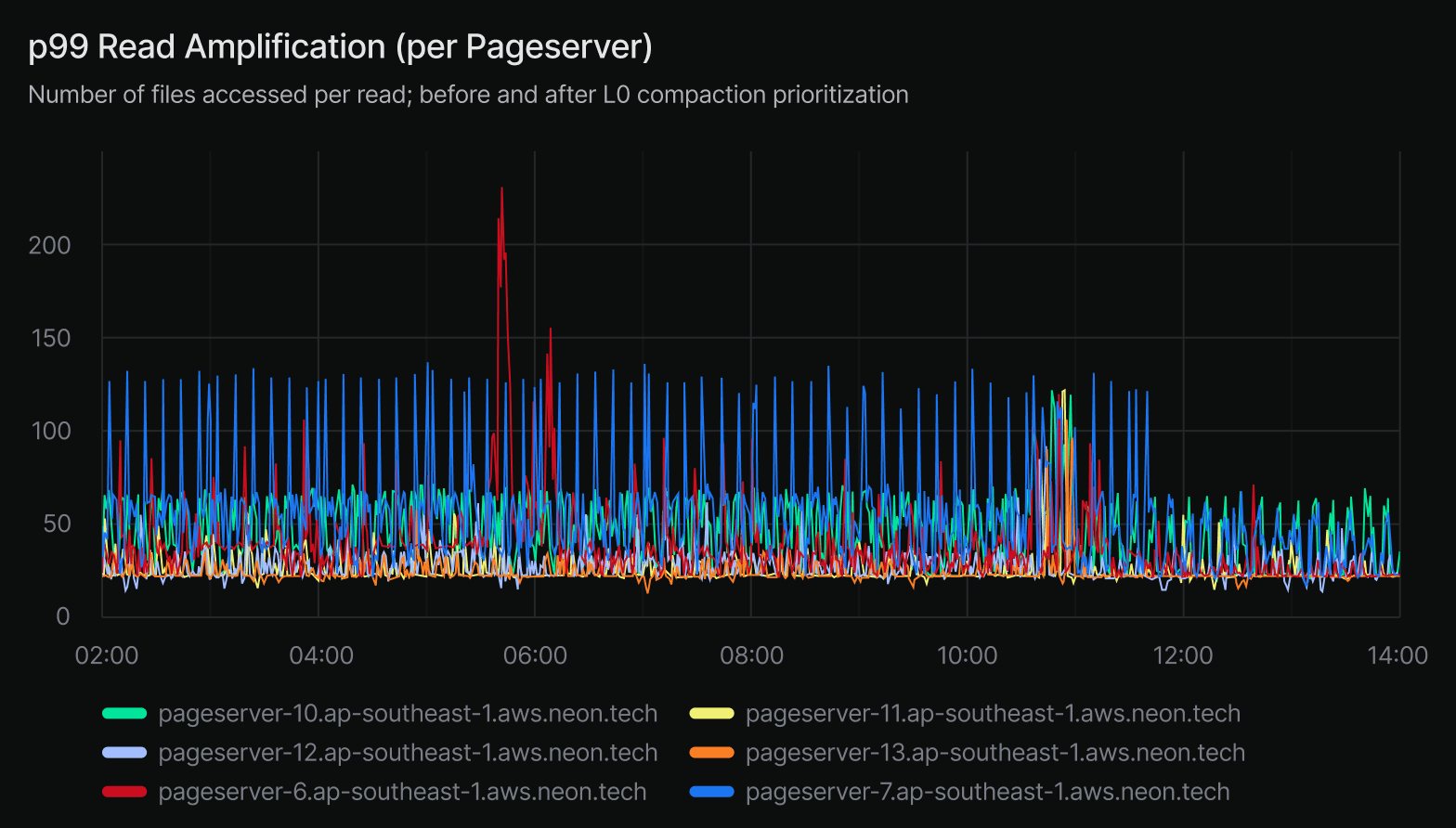
Previously, L0 compaction could be delayed by other background work, particularly L1 image compaction. This meant that under heavy ingestion, the system could accumulate hundreds of L0 files, severely impacting read latency. In some cases, the L0 layer count reached as high as 500, when the ideal range is fewer than 30.
We’ve changed our compaction policy to aggressively prioritize L0 work. L0 compaction now preempts background tasks like L1 compaction, and we apply backpressure to ingestion when the L0 count grows too fast. This ensures the Pageserver can keep up with compaction and avoids pathological read performance.
As a result, we’ve seen a dramatic drop in worst-case read amplification. The p99 read amplification metric has improved by over 50%, and maximum L0 layer counts have fallen from ~500 to under 30. This helps maintain low-latency reads even when tenants are ingesting large volumes of data.
Parallel, Pipelined S3 Uploads
TL;DR
How: Pageservers now upload layers in parallel and pipeline uploads with new file creation.
When Pageservers write data, they produce layer files that are uploaded to S3. Previously, this process was strictly sequential – write a layer file, upload it to S3, then move on to the next one. That left disk bandwidth underutilized during uploads and limited total throughput.
Pageservers can now pipeline this work: they begin uploading one layer file while continuing to write out the next. In addition, they’re allowed to upload multiple files in parallel where it’s safe to do so. This lets us better utilize both local disk and S3 network bandwidth.
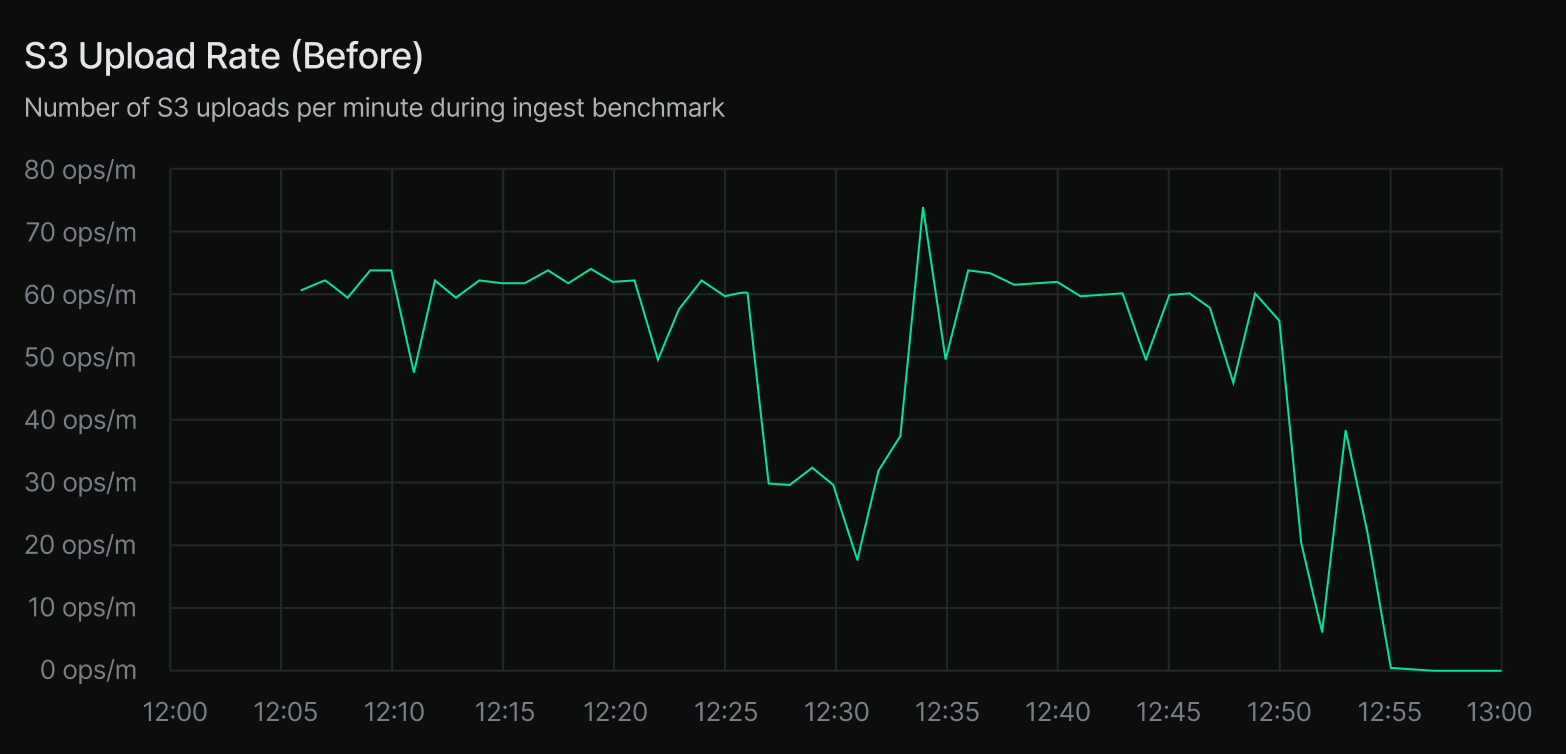
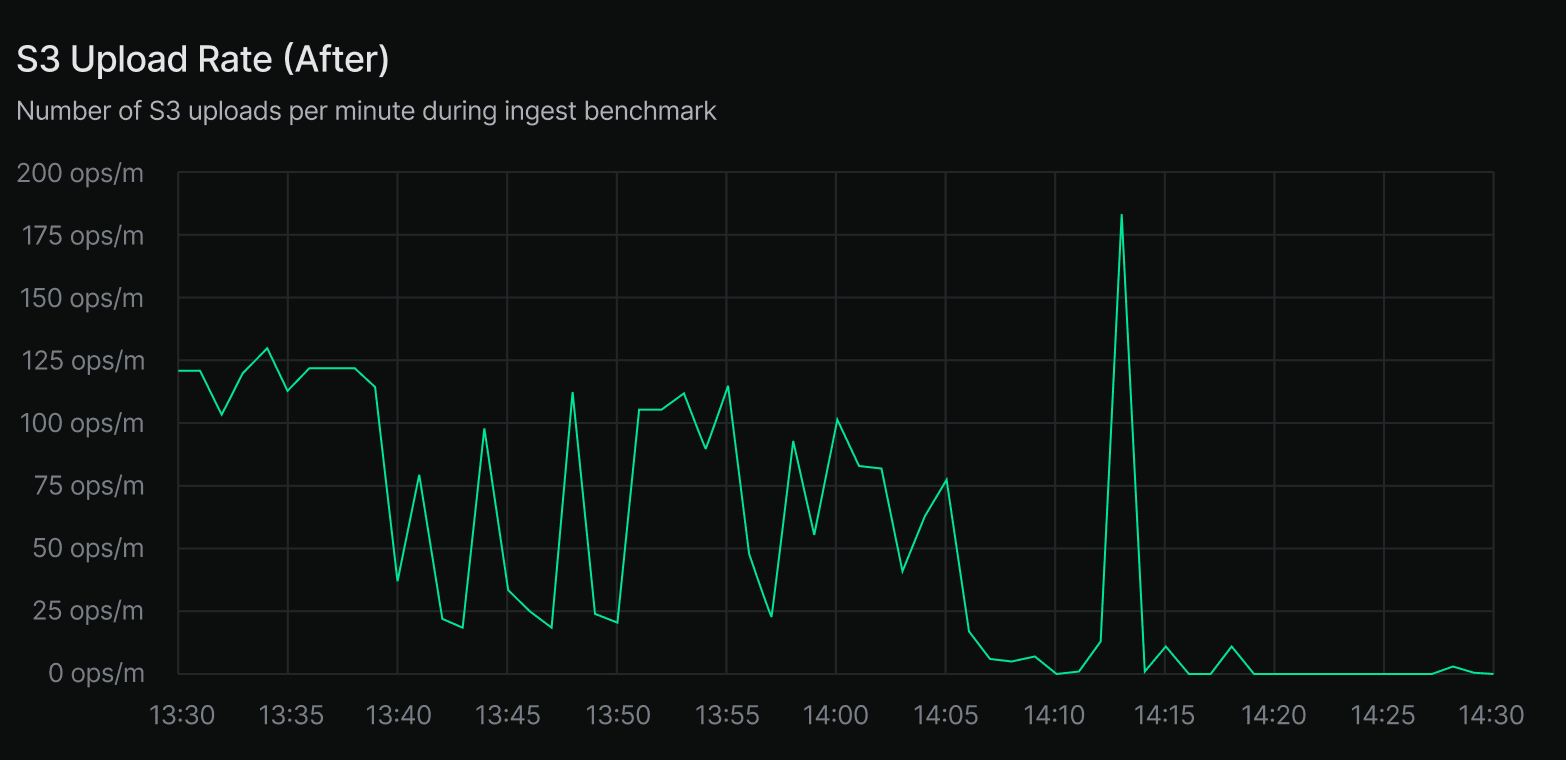
In our ingest benchmarks, we saw S3 upload throughput increase from 60 to 120 uploads per minute. More importantly, overall ingestion time dropped from 2 hours and 55 minutes to 2 hours and 24 minutes, a 30-minute reduction.
These improvements are especially important for large tenants and high-ingest workloads, where upload lag can otherwise become the bottleneck. This is a foundational optimization that also supports upcoming work on faster restores and recovery.
Improved Shard Split Policy
TL;DR
How: Shard splits now happen earlier and scale more gradually with tenant size.
Finally, let’s talk about shard splits. Neon shards large tenants across multiple Pageservers to distribute and scale out both read and write load. We previously used a single shard split threshold: tenants would split into 8 shards once they reached 64 GB. However, smaller tenants also benefit from sharding (especially with heavy read or update workloads), and larger tenants should continue to scale out as they grow.
We’ve therefore introduced a more granular split policy:
- At 16 GB, tenants now initially split into 4 shards
- At 1 TB, they split into 8 shards
- At 2 TB, they scale to 16 shards
This change enables better scalability for large tenants while also improving performance for smaller ones in the 16–64 GB range that previously remained unsharded. Early and adaptive sharding lays the foundation for more responsive storage behavior as tenant sizes grow, and ensures that performance scales more smoothly across tiers.
We’ll Keep Working in the Trenches
We’re not done yet. Performance is a moving target, and as more teams push Neon to its limits (e.g. the recent exploding of branches created by agents) we keep finding new bottlenecks to fix and new opportunities to go faster.
That said, the progress so far is real. The past few months have brought meaningful improvements across the storage layer. If you’re running large or write-heavy workloads on Neon, you’re already benefiting from this work.
More to come!